比Gemini Diffusion更全能!首个多模态扩散大语言模型MMaDA发布,同时实现强推理与高可控性
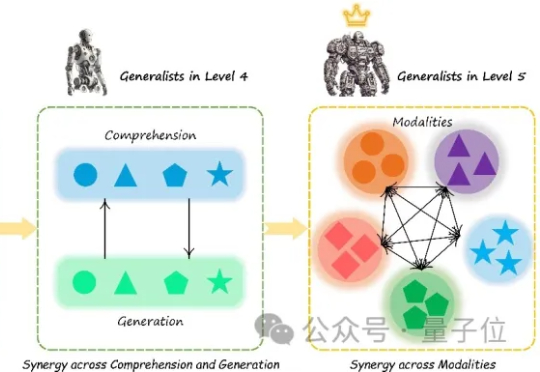
比Gemini Diffusion更全能!首个多模态扩散大语言模型MMaDA发布,同时实现强推理与高可控性普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
来自主题: AI技术研报
10477 点击 2025-05-22 17:30